Kun je vertrouwen op AI?
30
mrt
Geplaatst door: Charel van Ommeren
Categorie:
Informatief
Geen reacties

“ Google is my best friend “ is een veel gehoorde uitspraak als iemand op zoek gaat naar informatie. En toegegeven, het geboden aantal resultaten is een meer dan bovengemiddelde prestatie. Zeker als je je realiseert dat deze afkomstig zijn uit een groot aantal verschillende bronnen, zoals video, documenten, presentaties etc.
Tegelijkertijd accepteren wij dat de geboden resultaten niet helemaal aansluiten op hetgeen we zoeken. De wijze waarop we de zoekopdracht kunnen ingeven of met een open vraag een gesprek starten met een chatbot, geeft in veel gevallen een vorm van genoegdoening. Hoewel het antwoord niet volledig is, heeft het ons wel tot nadenken gezet en kunnen we ermee verder.
Toch is het voor bedrijven en overheden niet gewenst om met een half antwoord te komen. Klanten die informatie vragen moeten erop kunnen vertrouwen dat het resultaat volledig en correct is.
Gezien de steeds sneller toenemende hoeveelheid aan informatie moeten we ons bij het aangeboden resultaat steeds twee hoofdvragen stellen:
- Is de informatie die ik heb gevonden juist
- Is het aangeboden resultaat te herleiden en volledig
Herleiden van informatie
Het geven van een zoekopdracht om informatie te vinden is niet erg bijzonder. Wat wel bijzonder is, is om te begrijpen hoe het resultaat tot stand is gekomen. Artificial Intelligence (AI) is bij het zoeken en vinden een veel gebruikte toepassing. Door grote hoeveelheden gelijksoortige documenten aan te leveren, creëert AI een statisch model van alle aangeboden informatie. Dergelijke technologieën staan ook bekend als Cognitieve Search of Natural Language Processing (NLP). In veel gevallen wordt hier Machine Learning (ML) aan toegevoegd om de ongestructureerde data te verzamelen en te structureren zodat er een basis ontstaat om de content te gaan begrijpen.
Maar om de context van de content echt te kunnen begrijpen, dien je de taal te begrijpen. We noemen dit ook wel Natural Language Processing (NLP). Een veel gebruikte manier om dit te doen, is het handmatig zoeken naar gelijksoortige woorden en deze vast te leggen in een synoniemenlijst. In feite wordt hiermee een soort van mindmap gecreëerd. Hoe uitgebreider deze mindmap is, deze te beter de resultaten zullen zijn.
Aandachtspunt hierbij is wel, dat de mindmap zo goed is als de persoon die de woorden heeft toegevoegd. Naast de menselijke interpretatie van de totstandkoming van de synoniemenlijst, wordt er ook geen rekening gehouden met de grammaticale zinssamenstelling.
We kunnen dan ook concluderen dat het bij een AI-oplossing om een interpretatie van tekst gaat, gebaseerd op een statistische weging.
Het woord statistisch geeft ook al aan dat het een uitkomst is die het meest overeenkomt met gelijksoortige informatie. Een statische uitkomst is bij benadering 100%. Maar hoe de AI-engine het heeft bepaald, is niet duidelijk. De kwaliteit van het resultaat is zo goed als de leerset waarmee de engine is gevoed. Dit maakt het dan ook moeilijk met zekerheid vast te kunnen stellen waarom dit het document is dat we zochten.
U zult misschien denken, wat maakt dat kleine verschil nu uit? Maar als het document met de gewenste informatie die u zoekt niet door AI als juist is geclassificeerd, is er een reële kans dat u een foutieve beslissing neemt.
De oplossing zit in de Ambiguïteit
Hoewel er twee hoofdvragen zijn, is het resultaat te herleiden naar een centrale uitdaging. En dit is taaltechnologie, zonder gebruikmaking van AI. Hoe, zult u denken!
Taal is gebaseerd op grammaticale regels, zo ook de Nederlandse taal. Maar waar regels zijn, zijn er ook uitzonderingen. En de Nederlandse taal is complex vanwege deze uitzonderingen. De uitzonderingen kenmerken zich, doordat woorden of zinsverbanden in veel gevallen een dubbele betekenis kunnen hebben.
Laat ik het woord “bank” als voorbeeld genomen.
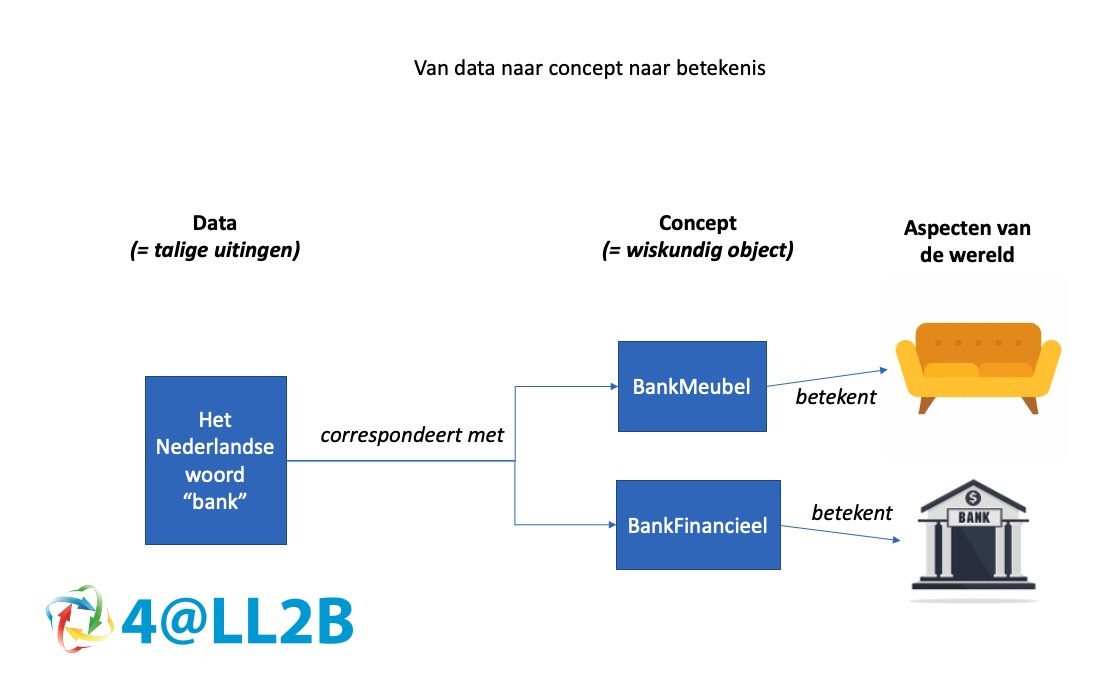
Als er staat:” Bij de bank waar ik werk, mag ik zitten op een bank”, heeft het woord bank twee verschillende betekenissen. Deze dubbelzinnigheid noemen wij ambiguïteit.
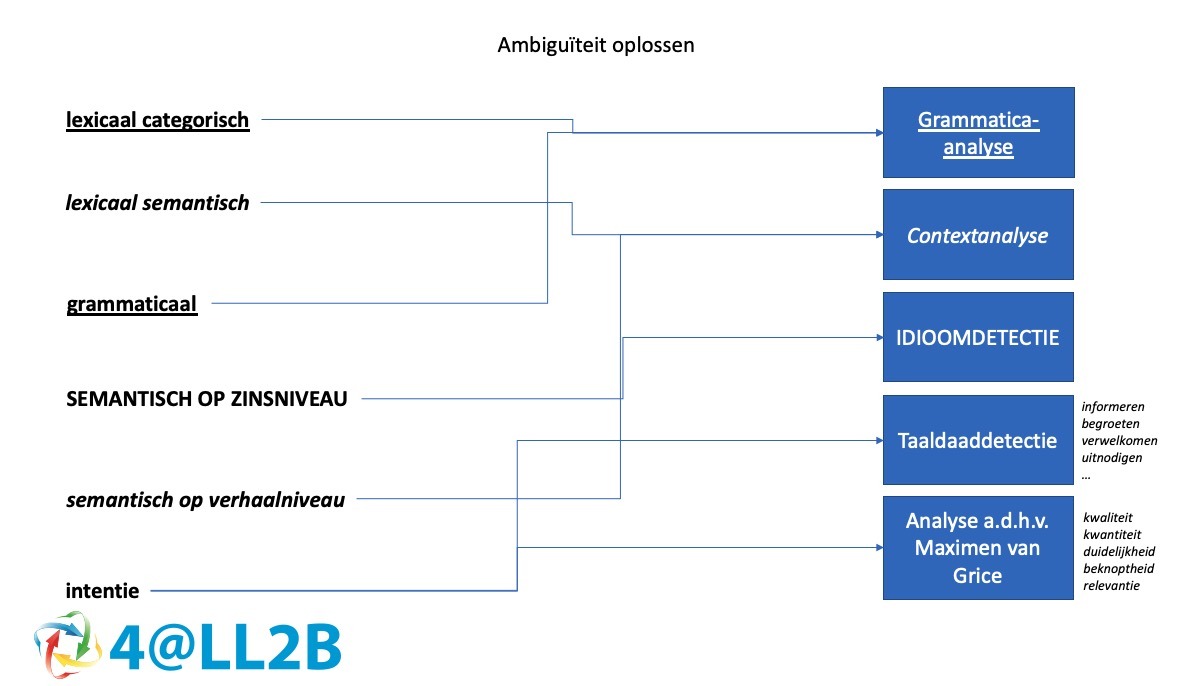
Helemaal volledig spreken we in dit geval over een lexiaal semantische ambiguïteit.
Naast deze kennen we ook lexicaal categorisch, grammaticaal, semantisch op zinsniveau, semantisch op verhaalniveau en intentie als vormen van ambiguïteit.
Laat ik nog een vorm (de grammaticale) van ambiguïteit toelichten.
Als er staat:” ik zie de persoon op het plein” kan dat meerdere betekenissen hebben.
Het kan suggereren dat de persoon op het plein staat; of dat ik strak een afspraak heb met de persoon op het plein.
De zinsopbouw van een tekst is in feite een dynamische puzzel die we met de verschillende ambiguïteitvormen moeten proberen op te lossen. In figuur 3 een weergave hoe dit eruitziet.
De combinatie van de ambiguïteitsvormen, vormen de hulpalgoritmes bij het begrijpend maken van de tekst. Taal is dynamisch, waardoor de hulpalgoritmes ook aan ontwikkeling onderhevig zullen zijn.
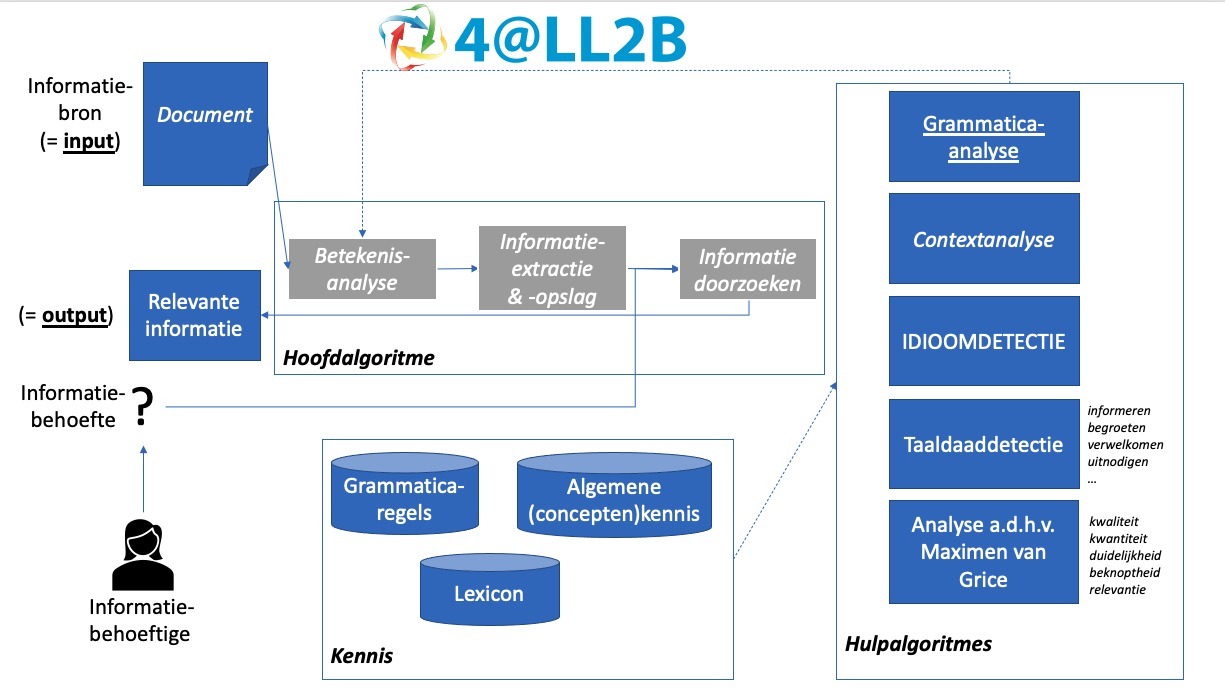
Dit hulpalgoritme kan niet zonder de grammaticale grondslag van onze Nederlandse taal die voor de eenvoud als “kennis” is benoemd.
De basis ligt echter bij het document. Zodra het document beschikbaar is als data is het digitaal toegankelijk en kunnen we deze gaan combineren met onze kennis en hulpalgoritmes. Zie ook Figuur 4.
Concluderend
De huidige zoek en taal gebaseerde oplossingen maken gebruik van Artificial Intelligence die gevoed worden door zgn. voorbeeld documenten. De uitkomst is door de engine bepaald op basis van een statistisch gegeven. Hierdoor is er geen zekerheid of het verkregen resultaat, het resultaat is wat we zochten. Terwijl herleidbaarheid steeds belangrijker wordt.
Taaltechnologie zonder Artificial Intelligence biedt de mogelijkheid om de juistheid van informatie en herleidbaarheid te verzorgen. Met het 4@LL2B platform komen hierin een groot aantal mogelijkheden beschikbaar.
- Automatische Document classificatie
- Contextuele documenteigenschappen in kaart brengen
-
-
- Zoeken en vinden
- Anonimiseren
-
-
- Document vergelijking
- De-duplicatie
- Samenvatten
- Tekst personalisatie (denk hierbij moeilijk begrijpbare teksten omzetten naar tekstueel uitlegbare teksten)
Vanuit deze mogelijkheden zijn vele toepassingen denkbaar:
- WOO applicatie, de zoekopdracht is herleidbaar naar de bron. Ook kan desgewenst worden gelakt en het document als digitaal toegankelijk worden afgeleverd.
- Contextuele Enterprise Search.
- Automatische document classificatie
- En nog veel meer
OD Solutions Nederland BV
Binnen OD-Solutions Nederland BV zijn wij van mening dat ieder proces start met een document.
Door onze jarenlange ervaring met document capturing hebben wij zeer veel ervaring wat documenten betekenen voor een organisatie. Het huidige Capture proces is veelal gebaseerd op het structureren van de content en deze te voorzien van indexsleutels die aansluiten op het proces. Zo archiveren wij op basis van bijvoorbeeld een kenmerk, zonder dat de inhoud van een document ertoe doet.
Aangezien we weten dat 80% van onze informatie ongestructureerd is, is het wenselijk dat we deze informatie kunnen gebruiken. Het vasthouden aan indexsleutels en generieke document kenmerken zorgen ervoor dat veel informatie verborgen blijft.
Om dit te verhelpen heeft hebben wij veel tijd gestoken in het ontwikkelen van taaltechnologie en deze ondergebracht in het platform 4@LL2B (spreek uit als For All To Be).